js实现pcm数据编码
前篇文章也讲了如何通过webrtc中的getUserMedia()方法和audioprocess事件获取音频的pcm数据了,接下来,我们就将这些数据做简单处理。虽然浏览器已经帮我们处理了模拟信号转数字信号的过程,但是我们还是有必要略微了解下的。
模拟信号
什么是模拟信号呢?非通信专业的我,引用来自维基百科的一段话:模拟信号(英语:Analog Signal),是指在时域上数学形式为连续函数的信号。(时域是描述数学函数或物理信号对时间的关系。例如一个信号的时域波形可以表达信号随著时间的变化。) 而我们先前录制的音频信号是带有音效的有规律的声波的频率、幅度变化信息载体。
类似于:
不过,这儿应该是很多很密的类似于正弦函数的曲线。
pcm编码
PCM(Pulse Code Modulation),脉冲编码调制,是一种模拟信号的数字化方法。
模拟信号数字化需要经过三个过程,即抽样、量化和编码,这儿就不详细介绍了。我们来看下pcm编码中几个比较重要的概念。
采样率
又可以称为采样频率,我们可以通过sampleRate得到输入的采样率:
var context = new (window.AudioContext || window.webkitAudioContext)();
console.log(context.sampleRate); // 输入音频采样率(HZ) 48000即横向坐标(可以理解为x轴)在单位时间内采集了48000(我的chrome输出这么多)次样本。从维基百科上偷张图来,加深下理解(先不管y轴)。因为采集的样本多,所以未处理的pcm编码占的空间都比较大,但是他未经过任何编码和压缩处理,是种无损压缩的格式,也能得到相当好的音质效果。

采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级,采样频率越高,音质越精确。正常人听觉的频率范围大约在20Hz~20kHz之间,根据奈奎斯特采样理论(只有采样频率高于声音信号最高频率的两倍时,才能把数字信号表示的声音还原成为原来的声音),为了保证声音不失真,采样频率应该在40kHz左右。所以对于高于48KHz的采样频率人耳已无法辨别出来了,所以并没有什么实用价值。
采样位数
采样位数可以用来描述连续变化的幅度值。 依旧是前面盗来的图,我们来关注下y轴上的信息,y轴共分为了16份,也就是2的4次方,即使用4bit就可以存储这些信息了,这儿的采样位数是4。将这些点连起来,是不是并不能完全(较好)地恢复原有的曲线?如果16份恢复地不够完美,那么32,64更多份数是不是就能恢复这波形图了呢?
一般情况下,采样位数是8或16,8位的可以划分为2^8=256份,范围是0-255。16位的可以划分位2^16=65536份,范围是-32768到32767。 到这就是量化了,采样位数这个数值越大,解析度就越高,录制和回放的声音就越真实。
可以打印看下先前我们搜集到的pcm数据,这些数据都是在[-1, 1]之间的,要转成8位的形式,负数*128,正数*127,然后整体向上平移128(+128),即可得到[0,255]范围的数据。16位的数据,只需要对负数*32768,对正数*32767即可。 注:实际存储都是二进制形式的。
声道
声道有单声道和双声道的区别,当然也有8位和16位之分,
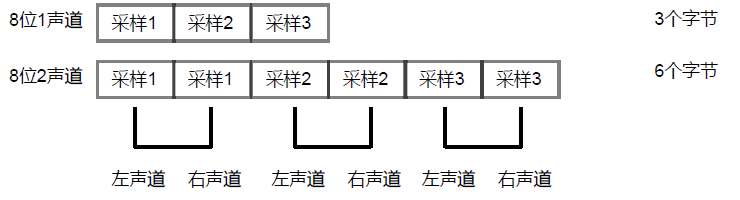
每个采样占用8bit,也就是一个字节。
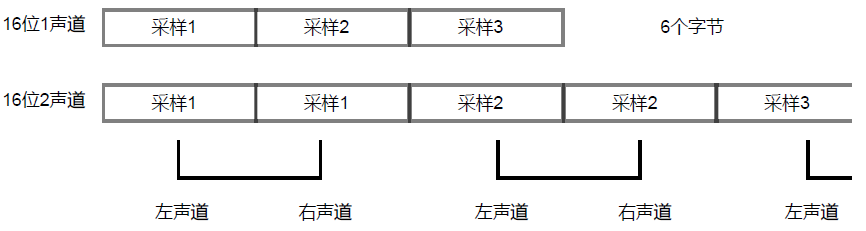
16位的就是double了。
双声道的话,在audioprocess事件种就要特殊处理下,可以用e.inputBuffer.getChannelData(1)取第二个声道的数据,当然,createScriptProcessor方法中的声道数也要设置成2。
注:双声道取得的数据不能直接使用,需要拼接成LRLRLR这种格式。
js实现转化
前面讲的差不多了,紧接着前一篇获取到[-1, 1]的pcm的代码。首先,在audioprocess事件中,是用inputData数组收集的,即是二维数组,为了后边处理方便,现处理成一位数组。
收集数据简单处理
function decompress() {
// 合并
var data = new Float32Array(size);
var offset = 0; // 偏移量计算
// 将二维数据,转成一维数据
for (var i = 0; i < inputData.length; i++) {
data.set(inputData[i], offset);
offset += inputData[i].length;
}
return data;
};size和inputData都是全局变量,当然这样写不好,这只是demo。因为audioprocess返回的也是Float32Array类型的数据,故此处接收容器也是Float32Array类型,关于该类型的详细介绍可以查看这篇文章:前端二进制学习(三)。
注:比如阿里云的语音识别,要求是16000采样率的pcm音频,所以,此处会有压缩的过程,由于48k与16k是三倍关系,即三个样本中要删除一个样本,利用循环过滤就可以了,不理解的可以查看recorder中的compress函数,我这没有做压缩采样样本。
编码
接下来就是编码了,我们这默认设置采样位数为16位。
var oututSampleBits = 16; // 输出采样数位由于8位刚好一字节,此处若是16位的采样位数,需要两倍的大小。所以,在取arraybuffer时,需要处理下,
let bytes = decompress(),
sampleBits = oututSampleBits,
dataLength = bytes.length * (sampleBits / 8),
buffer = new ArrayBuffer(dataLength),
data = new DataView(buffer);依据前面提及的算法,当采样位数是8位的,只要将负数*128,正数*127,然后整体向上平移128(+128)就可以了。
if (sampleBits === 8) {
for (var i = 0; i < bytes.length; i++, offset++) {
// 范围\[-1, 1\]
var s = Math.max(-1, Math.min(1, bytes\[i\]));
// 对于8位的话,负数\*128,正数\*127,然后整体向上平移128(+128),即可得到\[0,255\]范围的数据。
var val = s < 0 ? s * 128 : s * 127;
val = parseInt(val + 128);
data.setInt8(offset, val, true);
}
}当时16位的,只需要对负数*32768,对正数*32767就行了,记得offset取2,并使用setInt16,第三个参数要置为true,牵扯到大端和小端字节序。
for (var i = 0; i < bytes.length; i++, offset += 2) {
var s = Math.max(-1, Math.min(1, bytes\[i\]));
// 16位直接乘就行了
data.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}此时,data的数据就是处理后的pcm流数据了。
代码地址见:js实现pcm数据编码。
想要看js录音的可以看这篇文章:纯js实现录音与播放。
总结
到这,拿到手的pcm数据已经存储了对应的数据,可以使用了,比如阿里云语音识别就可以使用了。可惜,浏览器并不能播放pcm的音频数据,在下一篇中,将讲述下如何把pcm转成wav格式的音频文件,并在浏览器中播放。